




近年來,自動駕駛汽車技術廣受關注的原因固然是由於雷達、紅外線成像裝置、聲納、全球衛星定位系統(GPS)及其他各種感應器的成本逐漸降低,也是因為嵌入式系統的處理能力大幅提升之故。若是缺乏解讀資料所需的處理能力,不論擁有多麼精密或平價的成像技術也是枉然。
就此而言,嵌入式系統從「影像」中提取含意並據此內容達成分時決定(Split-second)的能力稱為視覺(Vision)。用於影像辨識的卷積神經網路(CNN)以其效率大幅推動產業前進。在微電子學方面,數位訊號處理器(DSP)開發素來是以滿足處理器的電力預算要求為主。同樣的優先順序,適用於嵌入式CNN在汽車自動化方面的發展。
CNN電力需求大 嵌入裝置無力支援
益華電腦(Cadence)日前於美國矽谷舉辦的嵌入式神經網路高峰會中(Embedded Neural Network Summit),透過討論得知要將深度神經網路(Deep Neural Networks, DNN)成功運用於嵌入式裝置的關鍵在於電源管理。
目前,CNN採用的最新技術是使用40W/TMAC(每兆倍累加運算瓦特數),而一般應用需要4TMAC,因此電力需求是160瓦(W),也就是說,現有嵌入式裝置的電力預算(Power Budget)根本無法容納。
此一問題有四個解決辦法,包括優化問題定義(儘量降低待處理畫素的數量)、儘量降低表示法中的位元數量(降低每次增殖價值)、優化網路架構(盡量減少每一畫素的增殖數),以及運用CNN優化硬體(減少晶圓層級電力)。
接下來,詳細說明這四種在複雜視覺應用中處理大量資料時的電力轉換方法。
優化問題定義 降低待處理像素
第二個問題在於如何降低畫素分割的大小。該如何讓系統知道一個包含各式各樣雜訊在內的影像內容,其實是路面上有一隻被汽車頭燈嚇傻的鹿,然後期待系統能夠分辨出路、地平線、信箱、圍籬、鹿,還有對向來車?系統如何得知視野中包含危險物,因此必須立刻停止車輛?在一張375×1,242畫素的影像中,有將近466,000個畫素需要「分類」。把這個影像乘以時間單位(動態照片),總共的資料量會多到讓人不知道該怎麼處理。
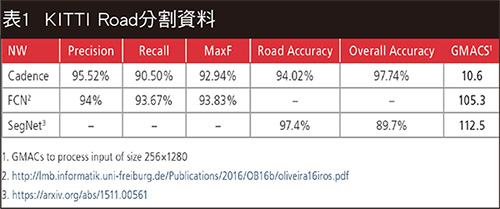
當然,神經網路能夠對重要像素資訊進行優先排序或分割。卷積網路不是一次只處理一個像素,而是透過將像素分為像素池的區塊方式進行處理,然後將之送入過濾器。這個過濾器又稱核心,是一個小於影像本身的矩陣,深度則與輸入的區塊相同。過濾器的工作是找出像素中的模式,它在來源上疊層,可能會有多層以利確認不同特徵(例如邊緣、轉角、橫/直線、顏色等等)。一旦辨識出特徵,系統就能夠依據內容做出一些決定(圖1、表1)。
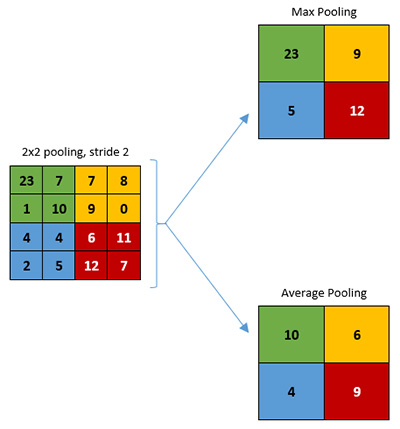 |
| 圖1 Stride與Pool |
 |
根據研究,可「重新定義地面真相」,用特徵來分割影像(而非逐一檢查像素),將問題縮小到二十二分之一。
減少位元數量 CNN先進量子化
CNN的訓練過程包括指定特定結果的加權向量,並對該等結果施行適性濾波以判定該輸入的陽性、偽陽和陰性部分。指定權重又稱為量子化程序,其發生分為兩種流程:
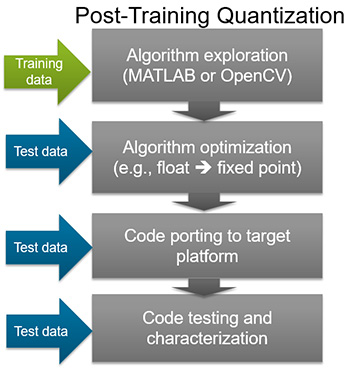
.訓練後量子化
此流程是在收集資料並依據訓練中出現的模式指定權重後集中處理結果(圖2)。
 |
| 圖2 訓練後量子化流程 |
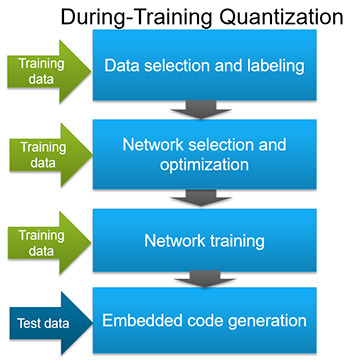
.訓練中量子化
此流程包含對輸入向量進行若干實例的「教導」(又稱預設);運算輸出及錯誤;運算這些實例的平均梯度;並據以調整權重。以訓練組中的許多小組實例重複進行此程序,直到目標函數的平均值不再降低為止。然後,系統就可利用測試資料展開自行學習(圖3)。這第二種方法也稱為隨機梯度下降法(SGD)。
 |
| 圖3 訓練中量子化流程 |
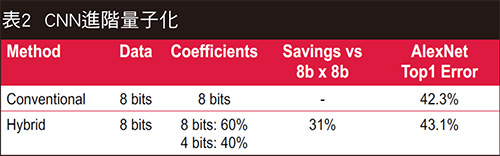
訓練後,用多組實例評量系統效能,藉此測試機器的歸納能力,也就是對於訓練時未曾見過的新資料產生合理答案的能力(表2)。
 |
不過,資料規模仍是十分龐大。這個問題有幾種解決方式,包括利用低準確度定點係數以及批次處理(Batching)。
利用低準確度定點係數可以較輕鬆地減少記憶體覆蓋區。當然,問題在於獲得的節省是否值得精確度的損失。
研究後發現若從16位元資料改為8位元資料、係數或兩者,精確度(1%或以下)的損失極小,但可將記憶體頻寬減少四分之一(相較於浮點),或二分之一(相較於使用16位元表示法)。
圖4為使用德國交通標誌基準(GTSB)的圖表,此為視覺辨識的最佳案例測試,因為要辨識的標誌數量不多,並且已經設計為在能見度不佳的條件下容易辨識的情況。
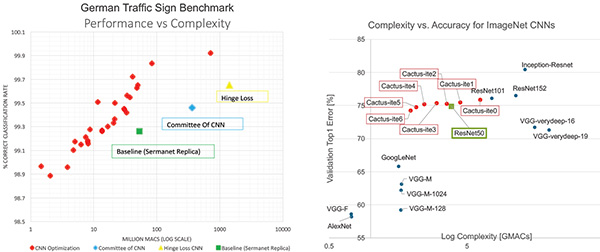 |
| 圖4 性能表現、複雜度與複雜度、準確性的比較 |
8位元運算消耗的電力少於32位元(或16位元)運算,且伴隨頻寬降所減少的記憶體讀取耗電較少。更有甚者,8位元資料類型的單指令多數據指令(SIMD)架構產生的結果效能更好,因為8位元資料的可能運算次數是32位元資料的四倍,是16位元資料的兩倍。
接著,說明何為批次處理。全連接層資料密集,因此為負載綁定。批次處理是一次處理全連接層的多重框架,並重新利用載入係數,以批量大小平均頻寬,使其成為運算綁定。如此可以降低頻寬並提高效能。在此,以AlexNet為例說明批次處理成果(圖5)。
 |
| 圖5 AlexNet中之批次處理與頻寬 |
批量大小是參酌各種因素而定,包括雙倍資料率(DDR)延遲、本機記憶體大小、圖磚(圖窗)及步幅大小管理等等。之後,再用最大池化(Max-pooling)、平均池化及其他方式處理批量資料。
優化網路架構 減少畫素增殖數
在優化網路架構方面,廠商所開發的Tensilica Vision P6 DSP採用超長指令文字(VLIW) SIMD架構,支援同時產生一到五項可同時在64個8位元或32個16位元向量資料向量多重運算域上運行的作業。
再者,此程序可付諸自動化。名為CactusNet的通用性超集合網路架構,可漸次優化分析以取得所需的靈敏度。CactusNet若與GTSRB搭配,可產生優異成果。CactusNet的辨識率不亞於其他知名系統,卻能將複雜度降低兩個數量級。
解決資料效率問題的終極方法是利用CNN優化網路,例如Tensilica Vision P6 DSP。此項產品結合先進VLIW/SIMD支援與每一處理器周期的大量計算邏輯單元(ALU)運算,並提供彈性記憶體匯流排。